
معرفی YOLOv11 جهشی بزرگ در بینایی کامپیوتری
انتهای مدل های بینایی ماشین

در دنیای پرشتاب هوش مصنوعی و بینایی کامپیوتری، مدلهای YOLO (You Only Look Once) همواره به عنوان یکی از پیشروترین الگوریتمهای تشخیص اشیاء شناخته میشوند.
در این مقاله، به بررسی ویژگیها و بهبودهای کلیدی YOLOv11 میپردازیم و نشان میدهیم که چگونه این نسخه جدید میتواند در پروژههای بینایی کامپیوتری شما تحول ایجاد کند.
ویژگیهای کلیدی YOLOv11
1. استخراج ویژگیهای پیشرفتهتر
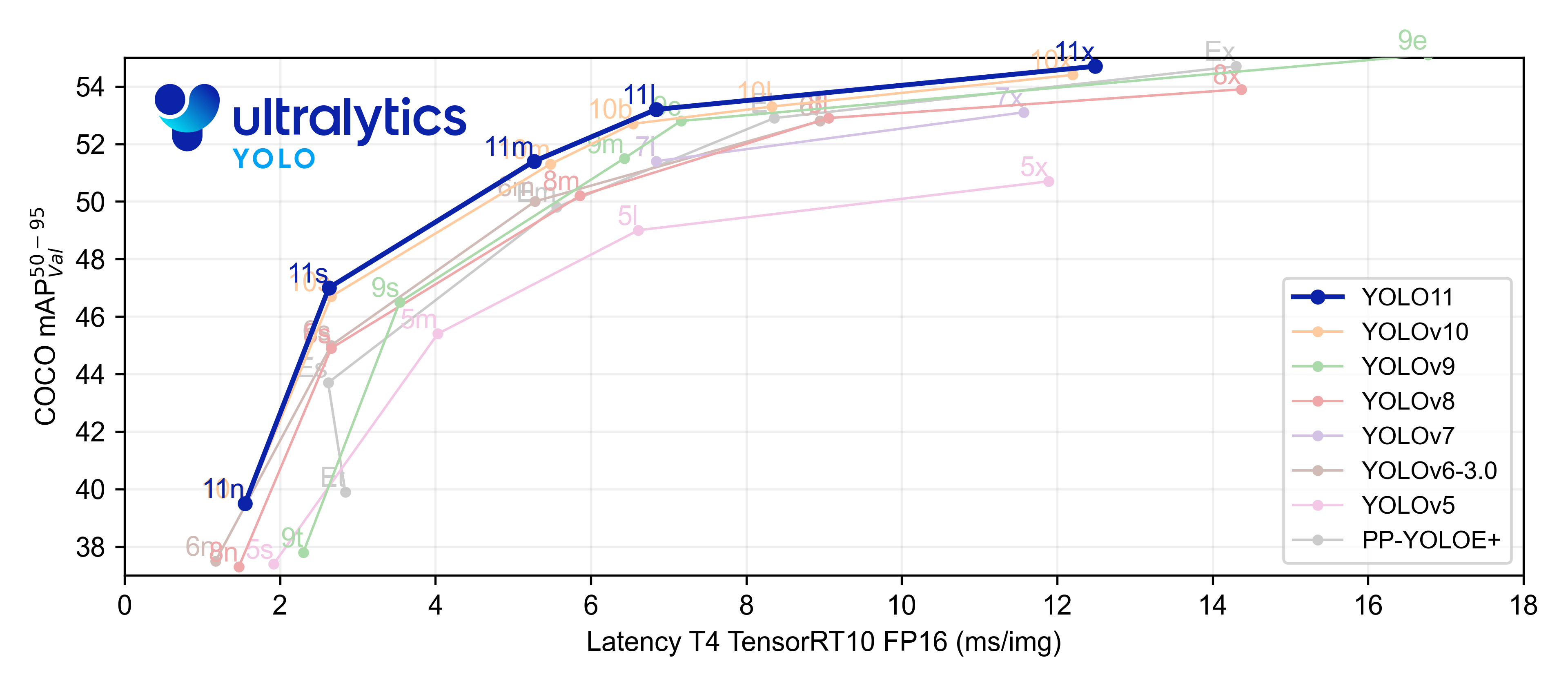
YOLOv11 با بهکارگیری معماری بهبودیافته در بخشهای backbone و neck توانایی استخراج ویژگیها را بهبود بخشیده است. این امر منجر به دقت بالاتر در تشخیص اشیاء و عملکرد بهتر در وظایف پیچیده میشود.
بخش اولیه یک مدل تشخیص شی است که وظیفه استخراج ویژگی ها از تصویر ورودی را بر عهده دارد. این بخش شامل چندین لایه کانولوشنی است که به تدریج اطلاعات موجود در تصویر را از حالت خام به ویژگی هایی با سطح بالاتر تبدیل می کند. این ویژگی ها شامل اطلاعات مختلفی از جزییات کوچک مثل لبه ها و الگو های ساده تا ویژگی های پیچیده تر مثل اشیا و بخش های بزرگ تر می شود
در YOLO و بسیار از مدل های دیگرمعماری های معروفی مثل ResNet یا CSPDarknet به عنوان backbone به کار گرفته می شوند. تغییرات در معماری این بخش می تواند بر سرعت و دقت مدل تاثیر گذار باشد.
معماریهای محبوب برای neck شامل:
FPN (Feature Pyramid Network): که سطوح مختلف ویژگیها را در مقیاسهای مختلف با هم ترکیب میکند.
PANet (Path Aggregation Network): که اطلاعات را از هر دو جهت (بالا به پایین و پایین به بالا) برای بهبود قابلیت تشخیص ترکیب میکند.
این بخش باعث میشود مدل بتواند ویژگیهای مختلفی که در سطوح مختلف تصاویر وجود دارند (مثل اشیاء کوچک و بزرگ) را به خوبی به کار گیرد و دقت و توانایی مدل در تشخیص اشیاء مختلف افزایش یابد.
. بهینهسازی برای کارایی و سرعت
با طراحی معماریهای بهینهشده و پایپلاینهای آموزشی کارآمد، YOLOv11 سرعت پردازش را افزایش داده و تا 25% کاهش در تأخیر (Latency) را ارائه میدهد، بدون آنکه از دقت کاسته شود.
3. دقت بالاتر با تعداد پارامترهای کمتر
مدل YOLOv11m با استفاده از 22% پارامتر کمتر نسبت به YOLOv8m ، میانگین دقت بالاتری (mAP) را در دیتاست COCO به دست میآورد. این امر مدل را از نظر محاسباتی کارآمدتر میسازد، بدون اینکه به دقت آن آسیبی برسد.
4. سازگاری در محیطهای مختلف
YOLOv11 قابلیت اجرا در محیطهای متنوعی را دارد؛ از دستگاههای لبه (Edge Devices) گرفته تا پلتفرمهای ابری و سیستمهایی که از GPU های NVIDIA پشتیبانی میکنند. این انعطافپذیری امکان استفاده از مدل را در سناریوهای مختلف فراهم میکند.
5. پشتیبانی از گسترهای از وظایف
YOLOv11 برای پاسخگویی به نیازهای متنوع بینایی کامپیوتری طراحی شده است. این مدل از وظایفی مانند تشخیص اشیاء، سگمنتیشن نمونه، طبقهبندی تصاویر، تخمین Pose و تشخیص اشیاء با جعبههای محدودکننده چرخیده (OBB) پشتیبانی میکند.
بهبودهای قابل توجه نسبت به نسخههای قبلی
- معماری بهبود یافته مدلها: با تغییراتی در معماری، مدلها تصاویر را بهتر پردازش کرده و پیشبینیهای دقیقتری ارائه میدهند.
- بهینهسازی :GPU با انعکاس مدلهای مدرن یادگیری ماشین، آموزش مدلهای YOLOv11 بر روی GPUها منجر به سرعت و دقت بالاتر میشود.
- سرعت بالاتر: مدلهای YOLOv11 با بهینهسازیهای انجامشده، نسبت به نسخههای قبلی خود سرعت بیشتری دارند.
- تعداد پارامترهای کمتر: کاهش تعداد پارامترها به مدل اجازه میدهد سریعتر عمل کند، بدون اینکه دقت کاهش یابد.
- انعطافپذیری و پشتیبانی از وظایف بیشتر: با YOLOv11، امکان آموزش مدلها برای انواع مختلف اشیاء و تصاویر فراهم است.
چه چیزهایی با YOLOv11 عرضه میشود؟
تیم Ultralytics با ارائه YOLOv11، مدلهای متنوعی را در اختیار کاربران قرار داده است که شامل موارد زیر است:
- تشخیص اشیاء: تشخیص اشیاء در تصاویر پس از آموزش.
- سگمنتیشن تصویر: فراتر از تشخیص اشیاء، بخشبندی اشیاء در تصاویر.
- تخمین Pose: رسم وضعیت انسان با نقاط و خطوط پس از آموزش.
- جعبههای محدودکننده چرخیده (OBB): تشخیص اشیاء با جعبههای محدودکننده چرخیده.
- طبقهبندی: طبقهبندی تصاویر به کلاسهای مختلف پس از آموزش.
با استفاده از کتابخانه Ultralytics، این مدلها میتوانند برای:
- ردیابی (Tracking): ردیابی مسیر اشیاء.
- صادرات آسان: امکان صادرات مدلها در فرمتها و برای مقاصد مختلف.
- سناریوهای متعدد: آموزش مدلها برای اشیاء و تصاویر متنوع.