
معرفی pytorch
پایتورچ به دلیل سهولت استفاده، سرعت بالا، و انعطافپذیری عالی، به یکی از ابزارهای محبوب در حوزه علم داده تبدیل شده است. ویژگیهای برجسته شامل محاسبه خودکار مشتقات و گرافهای محاسباتی دینامیک است که توسعه و آموزش مدلهای پیچیده را سادهتر میکند

پایتورچ یک کتابخانه قدرتمند برای یادگیری ماشین و یادگیری عمیق است که توسط Facebook توسعه یافته است. این کتابخانه به دلیل سهولت استفاده، سرعت بالا، و انعطافپذیری عالی، به یکی از ابزارهای محبوب در حوزه علم داده تبدیل شده است. ویژگیهای برجسته PyTorch شامل محاسبه خودکار مشتقات (autograd) و گرافهای محاسباتی دینامیک است که توسعه و آموزش مدلهای پیچیده را سادهتر میکند
برای شروع کار با PyTorch، نصب و راهاندازی محیط مناسب اهمیت دارد. برای ویندوز 10، میتوانید PyCharm را از وبسایت رسمی آن دانلود و نصب کنید. سپس، با استفاده از PyCharm، میتوانید کتابخانههای مورد نیاز مانند `pandas` را نصب کرده و محیط خود را برای کار با دادهها آماده کنید. برای راهنمایی بیشتر، وبسایتها و ویدیوهای آموزشی متعددی در دسترس هستند که میتوانند کمککننده باشند.
من با Jupiter notebook شروع کردم ولی بعد طبق راهنمایی استادم متوجه شدم مزایای pycharm بیشتر هست. برای همین یکباره با نصب pycharm شروع میکنیم.
Pytorch چیست؟
Pytorch چیزی هست که با نصب کردن آن در پایتون میتوانید با تانسور ها کار کنید.
پایتورچ در 100 ثانیه
بهتر است که قبل از یادگیری پایتورچ تجربه ی کار کردن با پاتون را در حد مقدماتی داشته باشید.
نصب و راه اندازی pytorch و pycharm
فعلا به نصب بپردازیم و بعد با انجام تمرین به یادگیری و استفاده از پاتورچ میپردازیم.
اول از همه شما باید پاتون را در لپتاپ خود داشته باشید:
برای نصب پایتون در لپتاپ، میتوانید به مراحل زیر عمل کنید:
دانلود پایتون:
به وبسایت رسمی پایتون python.org مراجعه کنید.
نسخهی مناسب برای سیستمعامل خود (ویندوز، مک یا لینوکس) را دانلود کنید.
نصب پایتون:
فایل نصبشده را باز کنید.
حتماً گزینه "Add Python to PATH" را در صفحه نصب انتخاب کنید.
روی "Install Now" کلیک کنید و منتظر بمانید تا نصب کامل شود.
بررسی نصب:
پس از نصب، یک ترمینال (یا Command Prompt در ویندوز) باز کنید.
دستور python --version یا python3 --version را وارد کنید تا از نصب صحیح پایتون مطمئن شوید.
نصب ابزارهای اضافی (اختیاری):
اگر نیاز به مدیریت بستههای پایتون دارید، میتوانید از pip استفاده کنید که همراه با پایتون نصب میشود.
برای نصب یک کتابخانه، از دستور pip install <package-name> استفاده کنید.
با این مراحل، پایتون به درستی در لپتاپ شما نصب خواهد شد و میتوانید شروع به برنامهنویسی کنید.برای نصب PyCharm و شروع به استفاده از PyTorch، مراحل زیر را دنبال کنید:
1. دانلود و نصب PyCharm
به وبسایت رسمی PyCharm بروید: PyCharm Download.
نسخه مناسب برای سیستمعامل خود را انتخاب کنید (ویندوز، مک، یا لینوکس).
نسخه Community (رایگان) یا Professional (با پرداخت) را دانلود کنید.
پس از دانلود، فایل نصب را اجرا کرده و PyCharm را نصب کنید.
پس از نصب، PyCharm را اجرا کنید.
2. نصب Python Interpreter در PyCharm
در PyCharm، به File > Settings > Project: <Your Project Name> > Python Interpreter بروید.
از قسمت بالا سمت راست روی علامت "+" کلیک کنید و مسیر نصب پایتون را انتخاب کنید (بهطور معمول python.exe یا python3).
3. نصب PyTorch
ترمینال PyCharm یا Command Prompt سیستم خود را باز کنید.
دستور زیر را برای نصب PyTorch وارد کنید:
pip install torch torchvision torchaudio
این دستور آخرین نسخه PyTorch را به همراه کتابخانههای جانبی مورد نیاز نصب میکند.
4. شروع به استفاده از PyTorch در PyCharm
یک پروژه جدید پایتون در PyCharm بسازید.
یک فایل Python جدید ایجاد کنید (مثلاً main.py).
کد زیر را برای بررسی اینکه PyTorch به درستی نصب شده است، در فایل خود وارد کنید:
import torch
print(torch.__version__)
اگر شماره نسخه PyTorch بهدرستی چاپ شد، یعنی PyTorch با موفقیت نصب شده است.
معرفی تنسورها در PyTorch و PyCharm
1. تنسور (Tensor)
تنسورها، دادههای چندبعدی هستند که مشابه آرایههای numpy یا ماتریسها هستند. در PyTorch، تنسورها برای ذخیره و پردازش دادهها استفاده میشوند.
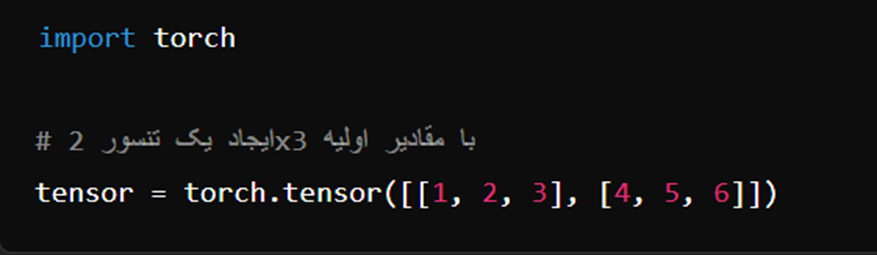
2. عملیاتهای ساده روی تنسورها
جمع و تفریق:
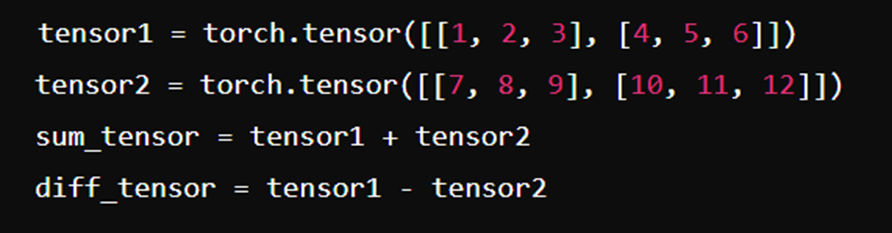
ضرب و تقسیم:

جمع کلی:

اندیسگذاری (Indexing)
اندیسگذاری یعنی دسترسی به عناصر خاص از تنسور.

برش (Slicing)
برش یعنی انتخاب بخشهایی از تنسور با استفاده از اندیسها.

وارد کردن و انجام عملیات روی فایل csv
وارد کردن و دستکاری دادهها در مجموعه داده Titanic
میتوانید ازین سایت فایل را دانلود کنید
https://www.kaggle.com/datasets/yasserh/titanic-dataset
1. وارد کردن فایل CSV
برای وارد کردن دادهها از فایل CSV در پایتون، از کتابخانه pandas استفاده میکنیم.

اگر ارور گرفتید برای نصب کتابخانه pandas در PyCharm، مراحل زیر را دنبال کنید:
باز کردن PyCharm:
برنامه PyCharm را باز کنید.
باز کردن تنظیمات پروژه:
از منوی بالای PyCharm، به File بروید و Settings را انتخاب کنید (در macOS به PyCharm و سپس Preferences بروید).
انتخاب Project Interpreter:
در پنجره تنظیمات، به Project: [نام پروژه] بروید و سپس Python Interpreter را انتخاب کنید.
افزودن پکیج جدید:
روی علامت + که در گوشه پایین سمت چپ قرار دارد، کلیک کنید تا لیست پکیجها باز شود.
جستجو و نصب pandas:
در کادر جستجو، عبارت pandas را تایپ کنید. سپس بر روی Install Package کلیک کنید تا نصب شروع شود.
تایید و بستن:
پس از نصب، میتوانید با کلیک بر روی OK یا Apply تنظیمات را تایید کرده و پنجرهها را ببندید.
حالا کتابخانه pandas در محیط PyCharm شما نصب شده و آماده استفاده است.
2. دستکاری دادهها
نمایش اولین سطرها:
print(data.head())
انتخاب یک ستون خاص:
ages = data['Age']
انتخاب سطرهای خاص بر اساس شرط:
survived = data[data['Survived'] == 1]
اضافه کردن یک ستون جدید:
data['NewColumn'] = 0
بهترین کار تمرین شخصی با همین دیتاست است.
چرا این مهم است؟
وارد کردن و دستکاری دادهها به شما امکان میدهد اطلاعات را آماده کنید، تحلیل کنید و الگوهای پنهان را کشف کنید. این مرحله برای هرگونه تحلیل داده و مدلسازی ضروری است.
آماده سازی داده چیست؟
آماده سازی داده ها فرآیند آماده سازی داده های خام برای پردازش و تجزیه و تحلیل است. این شامل جمعآوری، تمیز کردن و برچسبگذاری دادهها در قالبی مناسب برای الگوریتمهای یادگیری ماشین (ML) و به دنبال آن کاوش و تجسم دادهها است. این مرحله برای تجزیه و تحلیل دادههای موفق بسیار مهم است و اطمینان میدهد که دادهها دقیق، سازگار و قابل اعتماد هستند.
مراحل آماده سازی داده ها با مجموعه داده تایتانیک
1. داده ها را بارگذاری کنید
2. داده ها را بررسی کنید
3. ارزش های گمشده را مدیریت کنید
4. متغیرهای طبقه بندی را رمزگذاری کنید
5. مهندسی ویژگی
6. عادی کردن ویژگی های عددی
7. داده ها را تقسیم کنید
• بارگیری مجموعه داده:
• فایل CSV را با استفاده از Pandas در یک DataFrame بخوانید.
• رسیدگی به مقادیر گمشده:
• هر مقدار از دست رفته را بررسی کرده و مدیریت کنید. این میتواند شامل پر کردن آنها با یک مقدار خاص، حذف ردیفها/ستونهایی با مقادیر گمشده یا استفاده از تکنیکهای انتساب باشد.
• پاکسازی داده ها:
• هر گونه داده نادرست را حذف یا تصحیح کنید.
• در صورت لزوم به موارد تکراری رسیدگی کنید.
• تبدیل داده ها:
• عادی یا استاندارد کردن ویژگی های عددی.
• متغیرهای طبقهبندی را با استفاده از تکنیکهایی مانند رمزگذاری تک داغ یا رمزگذاری برچسب رمزگذاری کنید.
• مهندسی ویژگی: در صورت نیاز ویژگی های جدید را از ویژگی های موجود ایجاد کنید.
• تقسیم مجموعه داده:
• مجموعه داده را به مجموعه های آموزشی و آزمایشی تقسیم کنید (و در صورت نیاز مجموعه اعتبار سنجی).
• تبدیل تانسور:
• تبدیل داده ها به تانسور برای استفاده با TensorFlow و PyTorch.
مثال و تمرین بیشتر
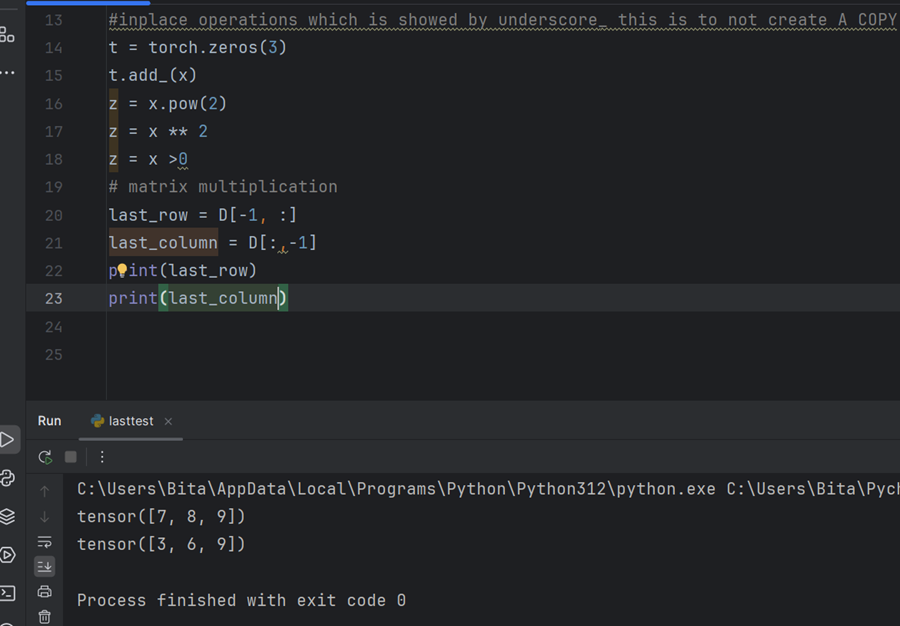
اگر در نمایه سازی یا برش بگوییم (-1،:) چه اتفاقی می افتد؟
-1 به معنای خط آخر است. این یکی آخرین سطر و همه ستون ها را می خواند، (:,-1) آخرین ستون تمام سطرها را چاپ می کند
اکنون یک مجموعه داده را پیدا کرده و یاد می گیرید که چگونه یک فایل csv را به pycharm وارد کنید و شروع به یادگیری نحوه چاپ 5 ردیف اول کنید. 3 راه برای این کار وجود دارد. یکی ارائه یک مسیر فایل است که به نظر من در حال حاضر ساده ترین راه است:
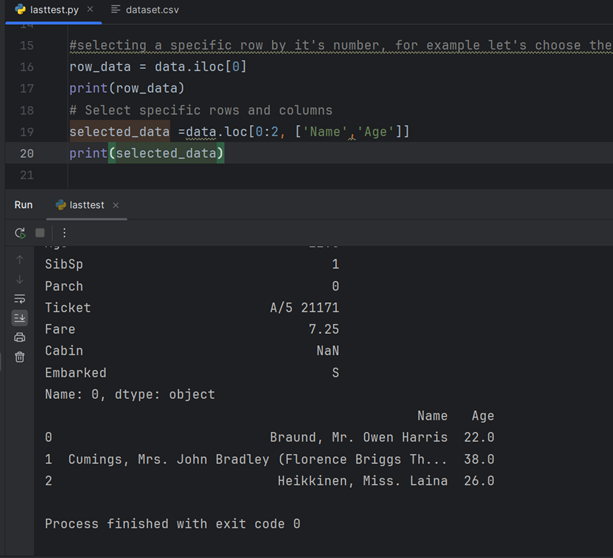
اکنون سعی کردم یکی از پایه ستون ها را با نام آن چاپ کنم
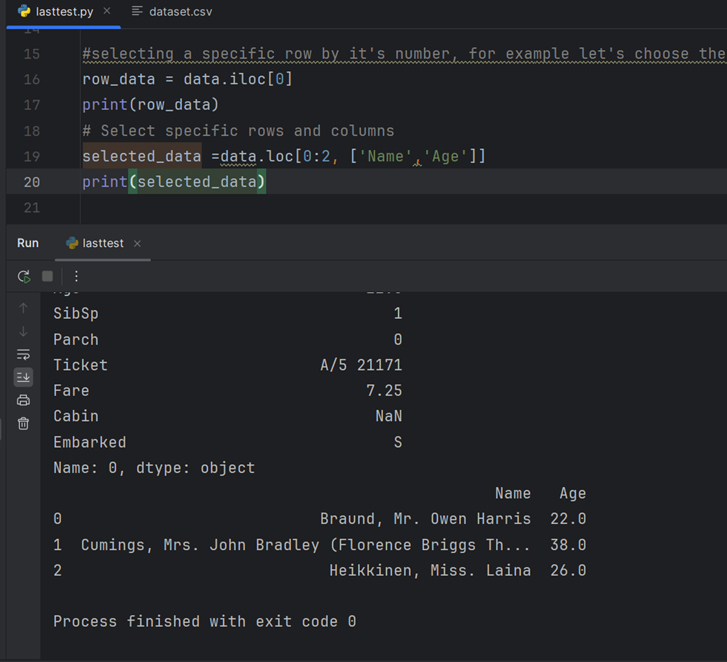
اکنون برای تمرین بیشتر:
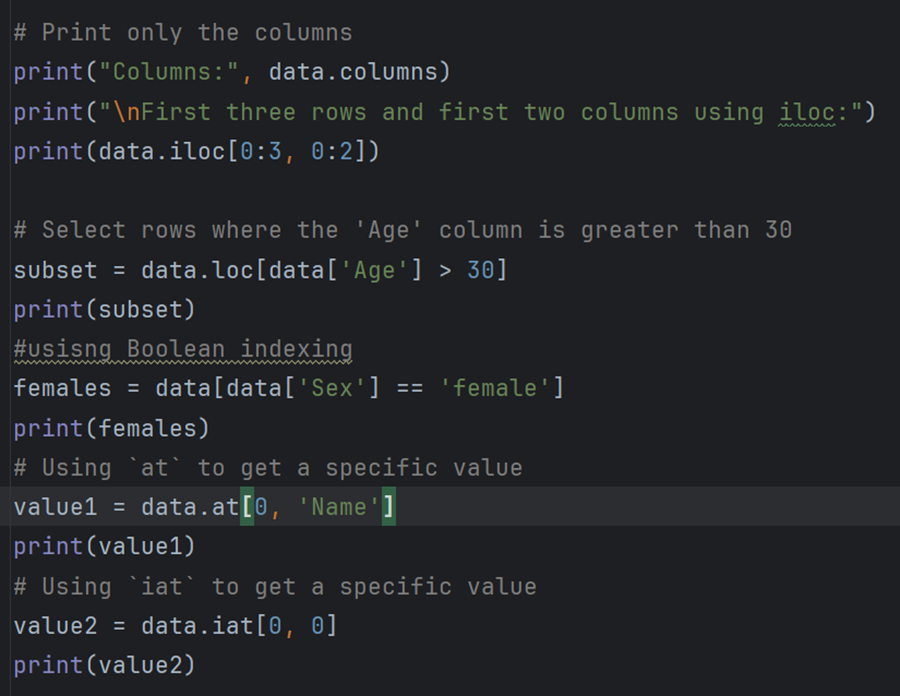
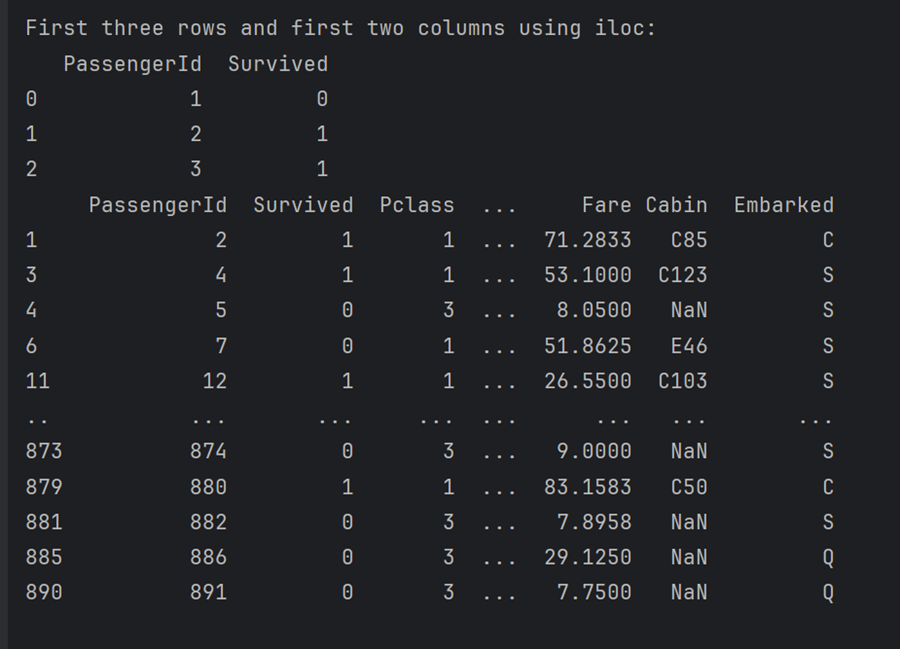
برای یادگیری نحوه چاپ ستونها با استفاده از iloc موقعیت عدد صحیح
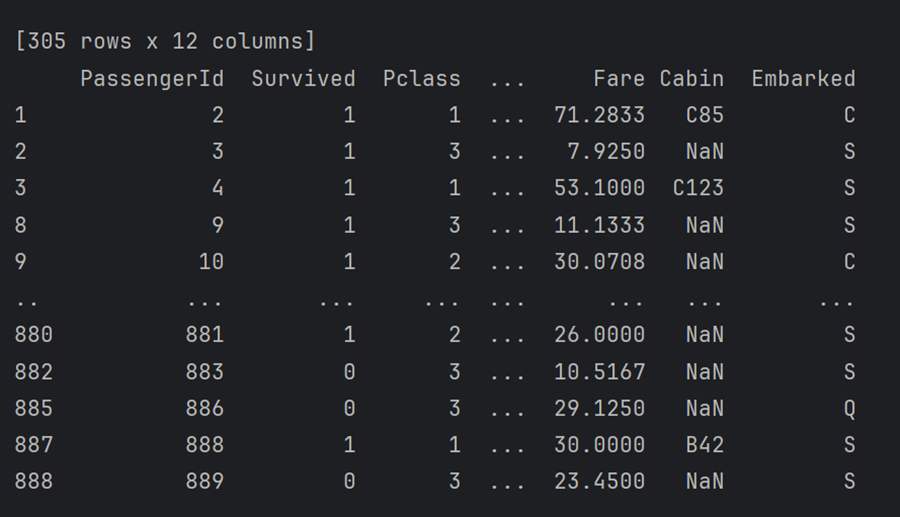
سپس چاپ ردیفهایی که سن مسافران بیش از ۳۰ سال است.
اینها روشهای مختلفی برای چاپ ردیفها و ستونهای خاص هستند.
یکی از آنها عبارتهای boolean است.
بنابراین در خط بعدی کد خود تمام دادههایی را که جنسیت زن است چاپ کردم.
و سپس ما "at" و "iat" داریم تا داده/مقدار خاصی را چاپ کنیم.
و اکنون برای یادگیری نحوه مدیریت دادههای ناقص، ابتدا باید بدانیم کدام خطوط دادهها را از دست میدهند با استفاده از این خط کد:
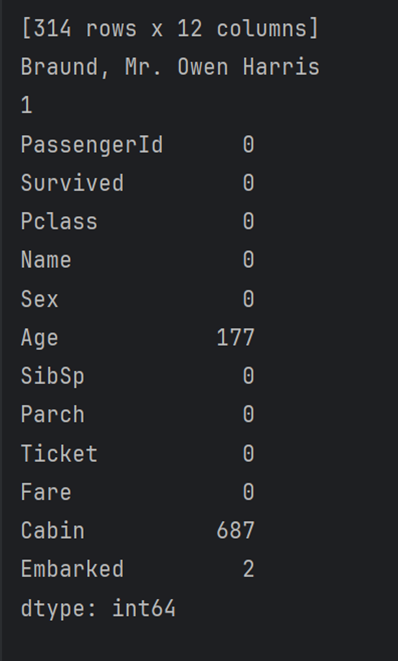
PassengerId, Survived, Pclass, Name, Sex, SibSp, Parch, Ticket, Fare:
این ستونها هیچ مقدار گمشدهای ندارند. همهی مقادیر در این ستونها کامل هستند.
Age:
این ستون ۱۷۷ مقدار گمشده دارد. از بین همهی مقادیر، ۱۷۷ مقدار بدون اطلاعات سنی هستند.
Cabin:
این ستون ۶۸۷ مقدار گمشده دارد. بخش بزرگی از اطلاعات کابین گمشده است.
Embarked:
این ستون ۲ مقدار گمشده دارد. ۲ مقدار در این ستون بدون اطلاعات محل سوار شدن ثبت شدهاند.
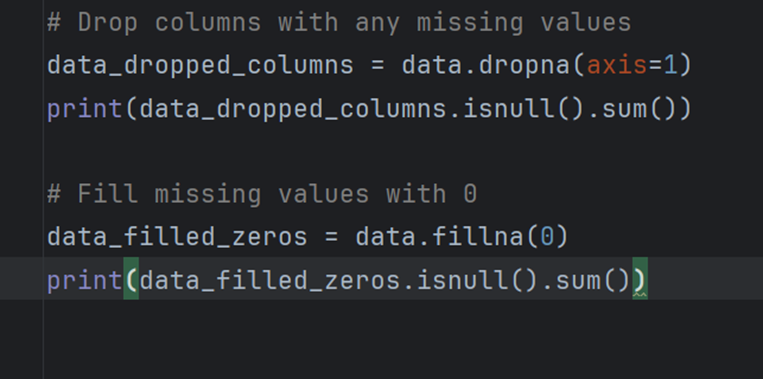
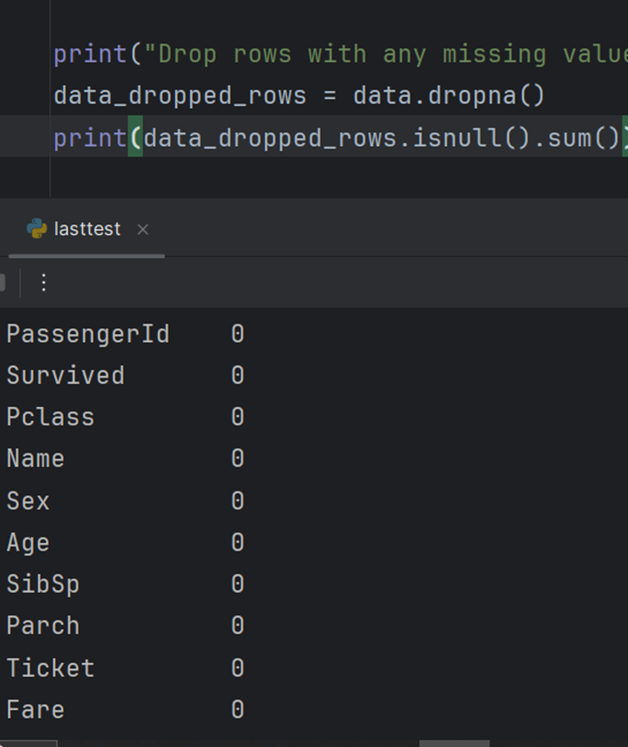
میتوانم این ردیفها و ستونها را حذف کنم یا مقادیر گمشده را با 0 پر کنم:
خلاصه
پایتورچ یک کتابخانه قدرتمند برای یادگیری ماشین و یادگیری عمیق است که توسط Facebook توسعه یافته و به خاطر سهولت استفاده و سرعت بالایش محبوبیت زیادی دارد. برای شروع کار با پایتورچ ، نصب و راهاندازی محیط مناسب مانندپایچارم ضروری است. پس از نصب PyCharm و Python، میتوانید کتابخانه پایتورچ را با دستور pip install torch torchvision torchaudio نصب کنید.
برای یادگیری نحوه کار با دادهها، به ویژه با مجموعه داده Titanic، میتوانید با استفاده از کتابخانه pandas فایل CSV را وارد کرده و دادهها را دستکاری کنید. این شامل بارگذاری دادهها، مدیریت مقادیر گمشده و انجام تحلیلهای ابتدایی است. استفاده از PyCharm و تمرینهای مختلف به شما کمک میکند تا با اصول دادهکاوی و تحلیل داده آشنا شوید و بتوانید به صورت مؤثر با دادههای واقعی کار کنید.
پینوشت
برای دانلود فایل CSV مجموعه داده Titanic، به [این لینک](https://www.kaggle.com/datasets/yasserh/titanic-dataset) مراجعه کنید. پس از دریافت فایل، میتوانید با استفاده از کتابخانه `pandas` در PyCharm، دادهها را بارگذاری کرده و عملیاتهای مختلف مانند مدیریت مقادیر گمشده و تحلیل دادهها را انجام دهید. برای راهنماییهای بیشتر، میتوانید از وبسایتها و ویدیوهای آموزشی مختلف بهرهبرداری کنید تا تسلط بهتری بر ابزارها و تکنیکهای مورد نیاز پیدا کنید.
راههای ارتباط:
ایمیل: bita.nf@gmail.com
لینکدین : www.linkedin.com/in/bita-farahmand-58363a232
توییتر: BitaBloom@