
بررسی سلامت مجموعه داده در بینا اکسپرتز
انجام "بررسی سلامت مجموعه داده" (Dataset Healthcheck) یک روش معمول در مواقعی است که مدلهای یادگیری ماشین بر روی مجموعه دادههای خاص آموزش داده میشوند.

انجام "بررسی سلامت مجموعه داده" (Dataset Healthcheck) یک روش معمول در مواقعی است که مدلهای یادگیری ماشین بر روی مجموعه دادههای خاص آموزش داده میشوند. این فرآیند برای ارزیابی و اطمینان از سلامت مجموعه داده استفاده میشود و هرگونه مشکلات یا نقصهای موجود در دادهها را بررسی میکند. در این پست میخواهیم در مورد اینکه چطور می توان اطمینان حاصل کرد که دادههای ما از نظر کیفیت، تعادل و قابلیت استفاده برای آموزش مدلها مناسب هستند صحبت کنیم.
عملیات مرتبط با "بررسی سلامت مجموعه داده" ممکن است شامل موارد زیر باشد:
· بررسی کیفیت دادهها (Data Quality Check): یک بررسی جامع از دادهها برای اطمینان از عدم وجود دادههای خارج از محدوده، دادههای نامناسب، تکراری یا هرگونه مشکلات کیفیتی دیگر.
· بررسی تعادل کلاسها (Class Balance Check): اطمینان از تعادل مناسب بین کلاسهای مختلف در دادهها برای جلوگیری از مشکلاتی مانند بیشبرازش یا کمبرازش در وظایف طبقهبندی.

· ارزیابی دادههای آموزشی و آزمایشی(Training and Testing Data Evaluation): ارزیابی دقیق دادههای آموزشی و آزمایشی برای اطمینان از اینکه با الزامات مدلها و اصول آموزشی مطابقت دارند.
· شناسایی نقصهای سیستماتیک(Systemic Defects Identification): شناسایی هرگونه مشکلات یا نقصها در فرآیند جمعآوری دادهها، پیشپردازش یا آمادهسازی دادهها که ممکن است به طور سیستماتیک دادهها را تحت تأثیر قرار دهند.
با انجام این عملیات، اطمینان حاصل میکنیم که دادههای ما آماده و مناسب برای استفاده در فرآیند آموزش مدل هستند و هرگونه مشکلات احتمالی که ممکن است بر عملکرد مدلها تأثیر منفی بگذارد، به طور کامل شناسایی و برطرف میشوند.
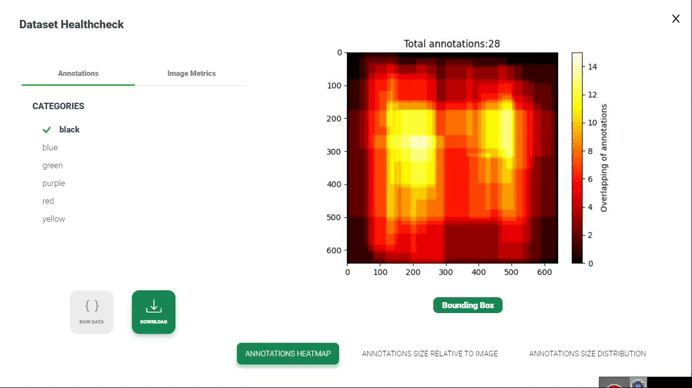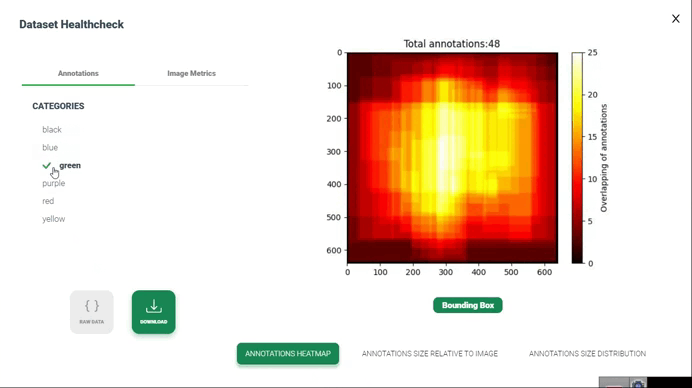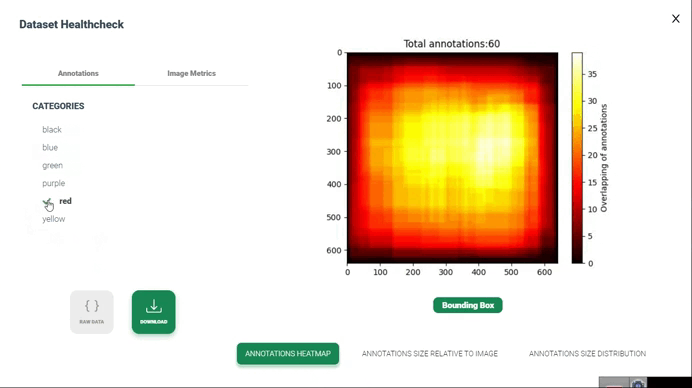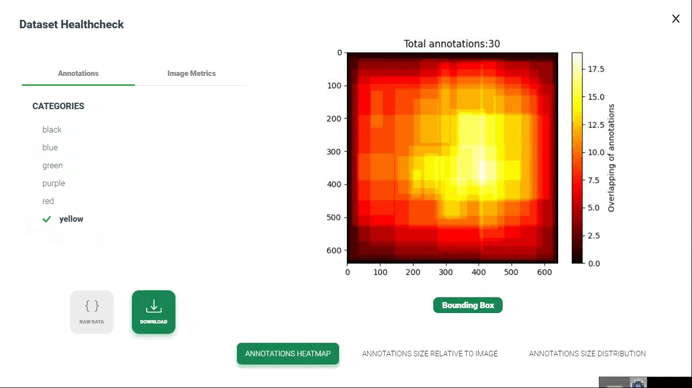
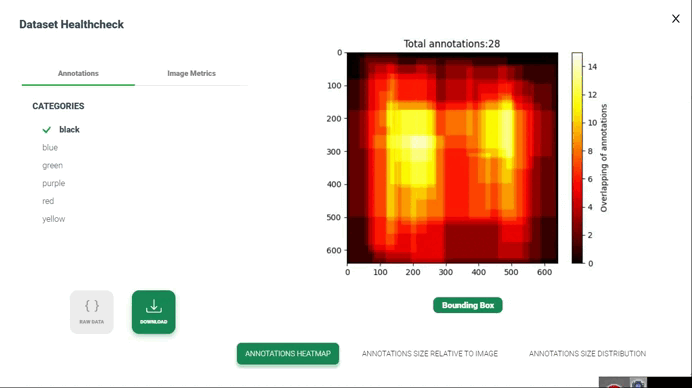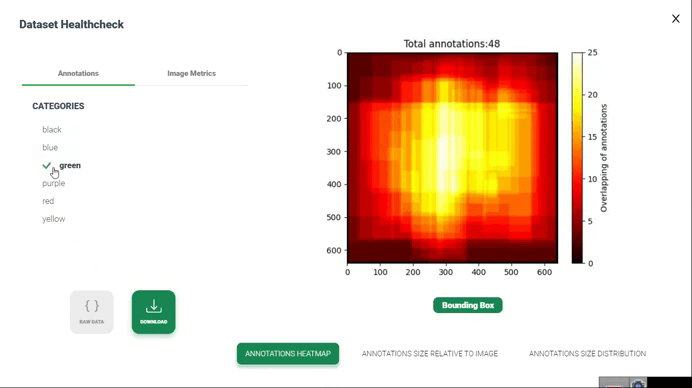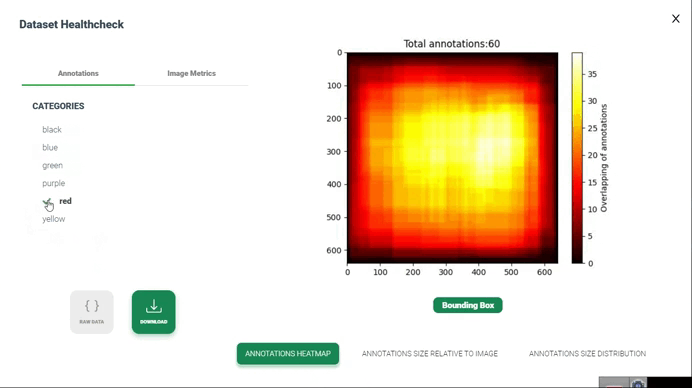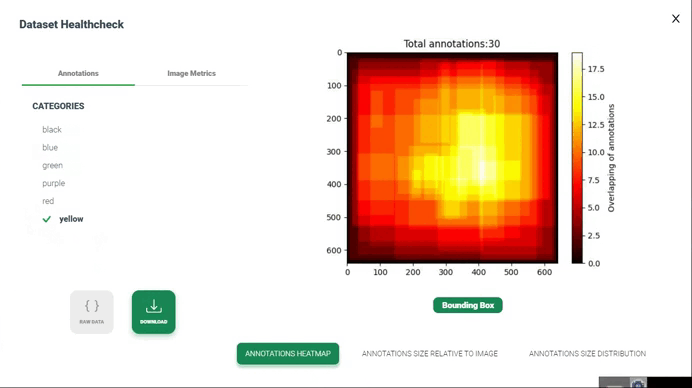
نقشه گرمایی حاشیهنویسیها
تولید نقشه گرمایی از همپوشانی حاشیهنویسیها در بررسی سلامت مجموعه داده شامل تصویرسازی نواحی است که حاشیهنویسیها توسط چندین حاشیهنویس یا حاشیهنویسیهای مختلف همپوشانی دارند. این تصویرسازی میتواند به شناسایی نواحی توافق یا اختلاف بین حاشیهنویسیها و ارزیابی کیفیت و انسجام حاشیهنویسیها کمک کند.
در اینجا یک روش کلی برای تولید نقشه گرمایی از همپوشانی حاشیهنویسیها آورده شده است:
1. آمادهسازی دادهها(Data Preparation): جمعآوری حاشیهنویسیها یا برچسبها برای مجموعه داده به همراه هرگونه فراداده اضافی مانند نام فایلهای تصویر یا شناسههای حاشیهنویسی.
2. محاسبه نواحی همپوشانی(Compute Overlapping Regions): برای هر تصویر یا نمونه در مجموعه داده، محاسبه نواحی همپوشانی بین حاشیهنویسیها. این معمولاً شامل مقایسه جعبههای محدودکننده، چندضلعیها یا ماسکهای بخشبندی حاشیهنویسیها و شناسایی نواحی است که در آنها تقاطع یا همپوشانی وجود دارد.
3. تجمع همپوشانیها(Aggregate Overlaps): تجمع نواحی همپوشانی بین حاشیهنویسیها یا حاشیهنویسان مختلف. بسته به مورد استفاده خاص، ممکن است بخواهید آماری مانند فراوانی همپوشانی یا نسبت حاشیهنویسیهایی که در یک ناحیه خاص توافق دارند، محاسبه کنید.
4. تولید نقشه گرمایی(Generate Heatmap): استفاده از تکنیک تصویرسازی نقشه گرمایی برای نمایش همپوشانیهای تجمعیافته. این میتواند شامل ایجاد یک شبکه یا تصویر باشد که هر پیکسل آن یک ناحیه از مجموعه داده را نشان میدهد و شدت رنگ پیکسل نشاندهنده درجه همپوشانی یا توافق بین حاشیهنویسیها در آن ناحیه است.
5. تصویرسازی(Visualization): نمایش نقشه گرمایی برای شناسایی الگوهای همپوشانی یا توافق در سراسر مجموعه داده. میتوانید از گرادیانهای رنگی برای نمایش شدت همپوشانی استفاده کنید، با رنگهای روشنتر که نشاندهنده سطح بالاتری از توافق یا همپوشانی هستند.
6. تفسیر و تحلیل(Interpretation and Analysis): تفسیر نقشه گرمایی برای ارزیابی کیفیت و انسجام حاشیهنویسیها. نواحی با توافق یا اختلاف بالا را بررسی کرده و در صورت نیاز تحقیقات بیشتری انجام دهید. این تحلیل میتواند به شناسایی نواحی بالقوه برای بهبود در فرآیند حاشیهنویسی یا برجسته کردن نواحی چالشبرانگیز در مجموعه داده کمک کند.
ابزارها و کتابخانههایی مانند OpenCV، Matplotlib یا Seaborn در Python میتوانند برای اجرای این جریان کاری و تولید تصویرسازی نقشه گرمایی مفید باشند. علاوه بر این، یکپارچهسازی تکنیکهای تصویرسازی تعاملی میتواند بهبود کاوش و تحلیل همپوشانی حاشیهنویسیها در مجموعه داده را افزایش دهد.
برای کسب اطلاعات بیشتر، شروع به کار و آشنایی با اجزای بینایی کامپیوتر موجود در پلتفرم بینا اکسپرتز، به https://binaexperts.com مراجعه کنید.