
هایپر پارامترها برای آموزش مدل در بینا اکسپرتز
هایپرپارامترها در آموزش شبکه عصبی به بچ ها، ایپاک ها و تعیین نوع gpu ها دسته بندی می شوند.


به طور کلی هایپرپارامترها در آموزش شبکه های عصبی شامل موارد اصلی زیر میباشد:
|
·
بچ ها، دسته ها(Batches) ·
ایپاک ها، دوره ها(Epochs) ·
نوع واحد پردازنده گرافیکی(GPU) |
بچها(Batches)
در آموزش شبکههای عصبی، اصطلاح "بچها" یا "دسته ها" به تعداد نمونههای دادهای اشاره دارد که به طور همزمان به شبکه عصبی داده میشود و در یک مرحله از فرآیند آموزش پردازش میشود. اندازه بچ یک پارامتر مهم در آموزش شبکههای عصبی است و میتواند به طور مستقیم بر کیفیت و سرعت آموزش تأثیر بگذارد. برخی از اثرات اندازه بچ عبارتند از:
1. آموزش سریعتر: استفاده از اندازه بچ بزرگتر میتواند به آموزش سریعتر منجر شود زیرا شبکه در هر مرحله از آموزش اطلاعات بیشتری دریافت میکند و بر اساس آن وزنها را بهروزرسانی میکند.
2. استفاده بهینه از منابع محاسباتی: استفاده از اندازه بچ بزرگتر میتواند به استفاده بهینهتر از منابع محاسباتی مانند پردازندههای GPU و حافظه منجر شود. از آنجا که شبکه در هر مرحله آموزش با دادههای بیشتری کار میکند، میتواند از این منابع بهطور موثرتری استفاده کند.
3. پایداری آموزش: استفاده از اندازه بچ بزرگتر میتواند به پایداری آموزش کمک کند. با افزایش تنوع دادههای ورودی که شبکه در هر مرحله میبیند، احتمال بیشبرازش کاهش مییابد.
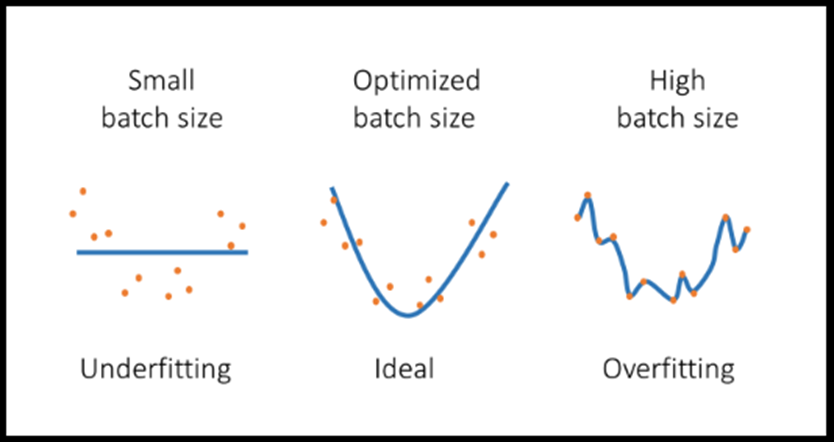
به طور کلی، انتخاب اندازه بچ باید بر اساس نیازهای خاص مسئله، منابع محاسباتی موجود و اهداف آموزشی انجام شود.
ایپاکها(Epochs)
یک ایپاک در آموزش شبکههای عصبی به یک فاز کامل از کل مجموعه دادههای آموزشی اشاره دارد. در هر ایپاک، الگوریتم آموزش بر روی کل مجموعه دادهها تکرار میشود، دادهها را در بچها به شبکه عصبی میفرستد، انتشار رو به جلو و عقب را انجام میدهد و پارامترهای مدل (وزنها و بایاسها) را بر اساس گرادیانهای محاسبه شده بهروزرسانی میکند.
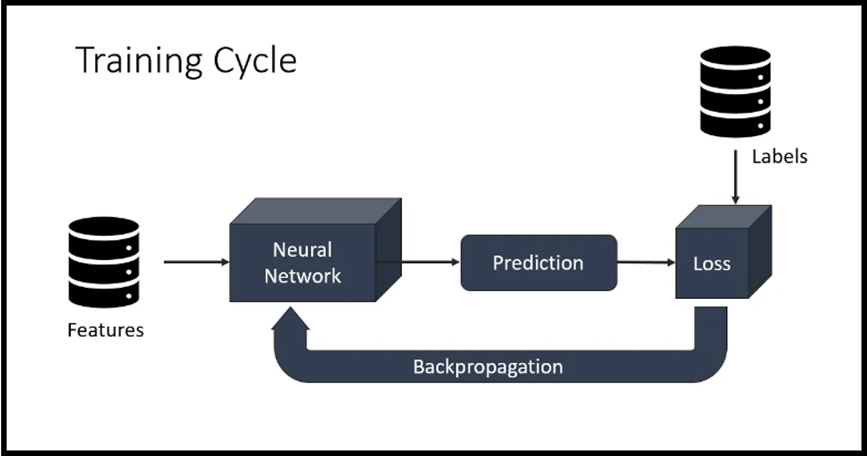
تعداد ایپاکهای یک پارامتر در آموزش شبکههای عصبی مهم است و تعیین میکند که الگوریتم آموزش چند بار بر روی کل مجموعه داده تکرار میشود. افزایش تعداد ایپاکها به مدل اجازه میدهد که دادههای آموزشی را چندین بار ببیند، که میتواند به همگرایی بهتر و بهبود عملکرد منجر شود. با این حال، استفاده از تعداد زیادی ایپاک میتواند خطر بیشبرازش را افزایش دهد، جایی که مدل دادههای آموزشی را حفظ میکند به جای آنکه الگوهای قابل تعمیم را یاد بگیرد.
انتخاب تعداد ایپاکها به عوامل مختلفی بستگی دارد، از جمله پیچیدگی و اندازه مجموعه داده، معماری شبکه عصبی و سطح عملکرد مورد نظر مدل. معمولاً مدل را در یک مجموعه داده اعتبارسنجی جداگانه در طول آموزش نظارت میکنند و آموزش را زمانی که عملکرد متوقف شود یا شروع به کاهش کند متوقف میکنند، که این تکنیک به عنوان توقف زودهنگام شناخته میشود. این کار به جلوگیری از بیشبرازش کمک میکند و اطمینان حاصل میکند که مدل به خوبی به دادههای دیده نشده تعمیم میدهد.
نوع پردازنده (GPU Type)
نوع GPU به مدل خاص یا معماری واحد پردازش گرافیکی (GPU) مورد استفاده در یک سیستم محاسباتی اشاره دارد. GPUها پردازندههای تخصصی هستند که برای انجام محاسبات موازی طراحی شدهاند و این ویژگی آنها را برای وظایف یادگیری عمیق مانند آموزش و استنباط شبکههای عصبی مناسب میسازد.

مدلهای مختلفی از GPU از تولیدکنندگان مختلف مانند NVIDIA، AMD و Intel وجود دارند. برخی از مدلهای رایج GPU از NVIDIA شامل موارد زیر است:
1. سری NVIDIA GeForce RTX: این GPUها عمدتاً برای بازی طراحی شدهاند اما عملکرد بسیار خوبی برای وظایف یادگیری عمیق ارائه میدهند.
2. سری NVIDIA GeForce GTX: این GPUها قدیمیتر از سری RTX هستند اما هنوز عملکرد خوبی برای بارهای کاری یادگیری عمیق ارائه میدهند.
3. سری NVIDIA Quadro: این GPUها برای برنامههای حرفهای مانند طراحی به کمک کامپیوتر (CAD) و ویرایش ویدئو بهینهسازی شدهاند اما میتوانند برای یادگیری عمیق نیز استفاده شوند.
4. سری NVIDIA Tesla: این GPUها به طور خاص برای محاسبات با عملکرد بالا (HPC) و برنامههای مرکز داده طراحی شدهاند، از جمله آموزش و استنباط یادگیری عمیق.
انتخاب نوع GPU به عواملی مانند بودجه، نیازهای عملکرد و در دسترس بودن بستگی دارد. برای وظایف یادگیری عمیق، GPUهای NVIDIA به دلیل عملکرد عالی و پشتیبانی از چارچوبهای یادگیری عمیق مانند TensorFlow و PyTorch بیشتر مورد استفاده قرار میگیرند. با این حال، AMD و Intel نیز GPUهایی ارائه میدهند که میتوانند برای یادگیری عمیق استفاده شوند، هرچند که با سطوح مختلفی از عملکرد و سازگاری با چارچوبهای یادگیری عمیق همراه هستند.
برای کسب اطلاعات بیشتر، شروع به کار و آشنایی با اجزای بینایی کامپیوتر موجود در پلتفرم بینا اکسپرتز، به BinaExperts مراجعه کنید.