
بهینهسازی هایپر پارامترهای پیشرفته
انتخاب بین بهینهسازهای Adam و SGD (گرادیان نزولی تصادفی) به عوامل مختلفی مانند ماهیت مسئله، مجموعهداده و معماری شبکه عصبی بستگی دارد.


انتخاب بین بهینهسازهای Adam و SGD (گرادیان نزولی تصادفی) به عوامل مختلفی مانند ماهیت مسئله، مجموعهداده و معماری شبکه عصبی بستگی دارد. در ادامه، مقایسهای بین این دو بهینهساز ارائه شده است:

(Adaptive Moment Estimation) Adam
Adam یک الگوریتم بهینهسازی با نرخ یادگیری تطبیقی است که مزایای هر دو الگوریتم AdaGrad و RMSProp را ترکیب میکند. این الگوریتم بهطور خاص برای وظایف یادگیری عمیق طراحی شده و از نرخ یادگیری متغیر برای هر پارامتر استفاده میکند.
مکانیزم:
Adam برای هر پارامتر نرخ یادگیری جداگانهای نگهمیدارد و نرخهای یادگیری را بر اساس مقدار اول و دوم گرادیانها تنظیم میکند. این ویژگی به Adam این امکان را میدهد که در شرایطی که گرادیانها نویزی هستند یا تغییرات شدیدی دارند، به خوبی عمل کند.
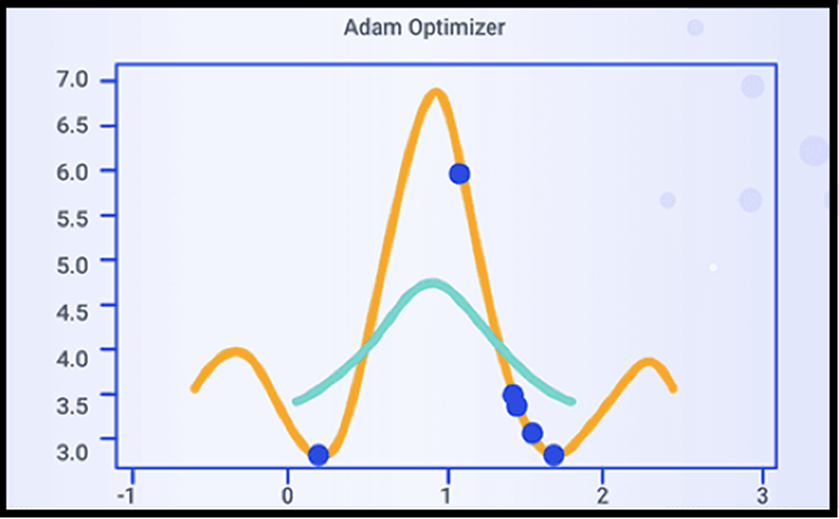
کاربرد:
Adam برای طیف گستردهای از وظایف یادگیری عمیق مناسب است و به دلیل همگرایی سریع و مقاومت در برابر نویز گرادیانها شناخته شده است. همچنین، نسبت به SGD نیاز به تنظیم دستی کمتری دارد که استفاده از آن را برای بسیاری از وظایف آسانتر میکند.
(Stochastic Gradient Descent) SGD
SGD یک الگوریتم بهینهسازی کلاسیک است که پارامترهای مدل را بر اساس گرادیانهای تابع هزینه نسبت به پارامترها بهروزرسانی میکند. این الگوریتم از دههها پیش مورد استفاده قرار گرفته و هنوز هم به دلیل سادگی و کارایی بالا مورد توجه است.
مکانیزم:
SGD از یک نرخ یادگیری ثابت برای همه پارامترها استفاده میکند و نرخ یادگیری را در طول آموزش تنظیم نمیکند. این ویژگی میتواند هم مزیت و هم عیب باشد؛ چرا که ثبات نرخ یادگیری میتواند به همگرایی بهتر کمک کند اما نیاز به تنظیم دقیق دارد.
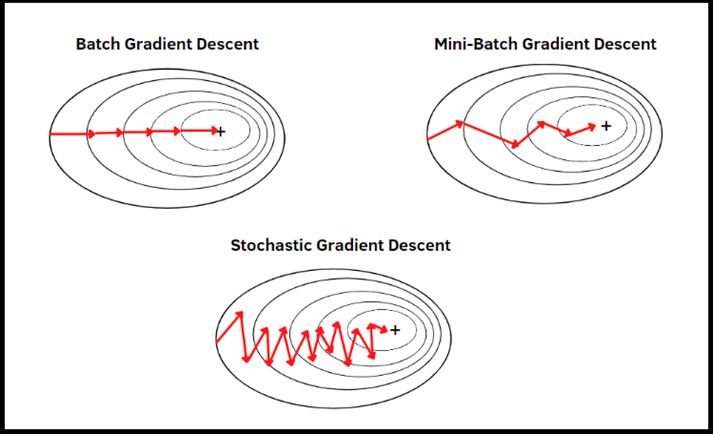
کاربرد:
SGD از نظر محاسباتی و حافظهای کارآمد است، به ویژه برای مجموعهدادههای بزرگ. علاوه بر این، در برخی موارد میتواند تعمیم بهتری نسبت به Adam داشته باشد، به این معنی که مدل بهتری برای دادههای جدید ایجاد میکند.
جمعبندی:
Adam معمولاً به دلیل مقاومت و سهولت استفاده به عنوان انتخاب پیشفرض برای وظایف یادگیری عمیق در نظر گرفته میشود. با این حال، SGD نیز میتواند مؤثر باشد، بهخصوص زمانی که به دقت تنظیم شود و در برخی موارد که کارایی محاسباتی یا تعمیمدهی اولویت دارد، ترجیح داده میشود. در نهایت، بهترین بهینهساز به نیازها و محدودیتهای خاص وظیفه بستگی دارد و توصیه میشود با هر دو بهینهساز آزمایش کنید تا مشخص شود کدامیک برای مسئله خاص بهتر عمل میکند.
بررسی دقیقتر:
برای درک بهتر انتخاب بین این دو بهینهساز، باید به چند عامل کلیدی توجه کنیم:
نوع مسئله: برای مسائل پیچیدهتر و شبکههای عمیقتر، Adam به دلیل تطبیقی بودن نرخ یادگیری معمولاً بهتر عمل میکند. اما برای مسائل سادهتر یا دادههای خیلی بزرگ، SGD میتواند به دلیل کارایی محاسباتی بالاتر گزینه مناسبی باشد.
تنظیمات هایپر پارامترها: یکی از چالشهای اصلی در استفاده از هر بهینهسازی تنظیم هایپرپارامترها مانند نرخ یادگیری است. Adam به دلیل تنظیم خودکار نرخ یادگیری نیاز کمتری به تنظیمات دستی دارد، در حالی که SGD نیاز به تنظیم دقیقتر نرخ یادگیری دارد.
تعمیمدهی: در برخی موارد، مدلهای آموزش دیده با استفاده از SGD عملکرد بهتری در مواجهه با دادههای جدید دارند. این به دلیل ماهیت تصادفی SGD و قابلیت آن در جلوگیری از بیشبرازش است.
پیشنهادات عملی:
آزمایش و ارزیابی: بهترین روش برای انتخاب بهینهساز مناسب، آزمایش هر دو الگوریتم بر روی مسئله مورد نظر و ارزیابی نتایج است. میتوانید از معیارهایی مانند دقت، همگرایی و کارایی محاسباتی برای ارزیابی استفاده کنید.
ترکیب بهینهسازها: در برخی موارد، ترکیب استفاده از Adam و سپس تغییر به SGD در مراحل پایانی آموزش میتواند به نتایج بهتری منجر شود. این روش میتواند از تطبیق سریع Adam و تعمیمدهی بهتر SGD بهرهبرداری کند.
نظارت بر گرادیانها: نظارت بر رفتار گرادیانها در طول آموزش میتواند به درک بهتر عملکرد بهینهساز کمک کند. برای مثال، اگر گرادیانها نویزی باشند، Adam ممکن است انتخاب بهتری باشد.
________________________________________
پی نوشت: با توجه به موارد فوق، انتخاب بهینهساز مناسب نیاز به دقت و آزمایش دارد. هر دو الگوریتم Adam و SGD دارای مزایا و معایب خاص خود هستند و انتخاب نهایی باید بر اساس نیازها و محدودیتهای خاص مسئله شما باشد.
برای کسب اطلاعات بیشتر، شروع به کار و آشنایی با اجزای بینایی کامپیوتر موجود در پلتفرم بینا اکسپرتز، به بینا اکسپرتز مراجعه کنید.