
شناسایی عوامل ارزیابی کیفی مجموعه داده های بینایی کامپیوتری
میتوان مجموعه دادههای با کیفیتی ایجاد کرد که منجر به توسعه مدلهای بینایی کامپیوتری دقیقتر و قابل اعتمادتر شوند.


در دنیای امروز، بینایی کامپیوتری به یکی از حوزههای مهم و پرکاربرد هوش مصنوعی تبدیل شده است. از تشخیص چهره گرفته تا خودروهای خودران، الگوریتمهای بینایی کامپیوتری نقش اساسی در توسعه و پیشرفت تکنولوژیهای مدرن دارند.
هر روش بینایی یادگیری ماشین حول مجموعه قابل توجهی از عکسهای برچسبگذاری شده ساخته میشود، صرف نظر از اینکه موضوع مورد بحث طبقهبندی تصویر، تشخیص شی یا ناحیه بندی باشد. اما هنگام رویارویی با مسائل یادگیری عمیق در بینایی کامپیوتر، طراحی یک استراتژی جمعآوری دادهها گامی حیاتی است که اغلب نادیده گرفته میشود. یکی از بزرگترین موانع یک پروژه یادگیری عمیق کاربردی موفق، مونتاژ یک مجموعه داده با کیفیت بالا است. دادههای با کیفیت نه تنها دقت و کارایی مدلهای بینایی کامپیوتری را افزایش میدهند، بلکه از بروز تعصبات و خطاهای احتمالی نیز جلوگیری میکنند.
در این مقاله، به بررسی عوامل مهمی که کیفیت دادههای بینایی کامپیوتری را تعیین میکنند، خواهیم پرداخت. با شناخت و اعمال این عوامل، میتوان مجموعه دادههای با کیفیتی ایجاد کرد که منجر به توسعه مدلهای بینایی کامپیوتری دقیقتر و قابل اعتمادتر شوند.
- کیفیت داده ها
تصاویر با کیفیت، نور، زوایا و فواصل دوربین را که در مکان مورد نظر یافت میشوند، تکرار میکنند. یک مجموعه داده با کیفیت بالا شامل نمونه های متمایز از موضوع مورد نظر است. به طور کلی، اگر شما قادر به تشخیص سوژه مورد نظر خود از روی یک تصویر نباشید، الگوریتم نیز قادر به تشخیص آن نیست. این قانون دارای استثنائات عمده ای است، مانند پیشرفت های اخیر در تشخیص چهره، اما مکانی عالی برای شروع است.
اگر دید شی مورد نظر سخت است، نور یا زاویه دوربین را تنظیم کنید. همچنین میتوانید دوربینی با زوم اپتیکال اضافه کنید تا تصاویر نزدیکتر با جزئیات بیشتر از سوژه را فعال کنید. در تصویری که در زیر نشان داده شده است، میتوانیم تصاویری با وضوح پایین در مقابل وضوح بالا مشاهده کنیم. اگر مدل را بر روی تصاویر با کیفیت پایین با وضوح پایین آموزش دهید، یادگیری مدل دشوار می شود. در حالی که تصاویر با کیفیت خوب به مدل کمک می کند تا به راحتی در کلاس های مورد نظر ما آموزش ببیند. کارایی و زمان مورد نیاز برای آموزش مدل تحت تأثیر کیفیت مجموعه داده مورد استفاده قرار می گیرد. از تصاویر تار یا خارج از فوکوس خودداری کنید، مگر اینکه این تصاویر به مشکلی که در حال بررسی است مربوط باشد.

- تعداد نمونه ها
هر پارامتری که مدل شما باید برای انجام وظیفه خود در نظر بگیرد، مقدار داده ای را که برای آموزش نیاز دارد افزایش می دهد. به طور کلی، هر چه نمونه های برچسب دار بیشتری برای مدل های بینایی آموزشی در دسترس باشد، بهتر است. نمونه ها نه تنها به تعداد تصاویر، بلکه به نمونه هایی از یک موضوع موجود در هر تصویر اشاره می کنند. گاهی اوقات یک تصویر ممکن است فقط شامل یک نمونه باشد که در مسائل طبقه بندی مانند طبقه بندی تصاویر گربه ها و سگ ها معمول است.
در موارد دیگر، ممکن است چندین نمونه از یک موضوع در هر تصویر وجود داشته باشد. برای یک الگوریتم تشخیص شی، داشتن تعداد انگشت شماری از تصاویر با چندین نمونه بسیار بهتر از داشتن همان تعداد عکس با تنها یک نمونه در هر تصویر است. در نتیجه، روش آموزشی که استفاده میکنید باعث ایجاد تغییرات قابل توجهی در میزان دادههای آموزشی مفید برای مدل شما میشود.

- تغییرپذیری
هرچه یک مجموعه داده تنوع بیشتری داشته باشد، آن مجموعه داده می تواند ارزش بیشتری برای الگوریتم ارائه دهد. یک مدل چشم انداز یادگیری عمیق به منظور تعمیم به نمونه ها و سناریوهای جدید در تولید نیاز به تنوع دارد. هنگامی که مدل با سناریوهای جدید مواجه می شود، شکست در جمع آوری مجموعه داده با تنوع می تواند منجر به برازش بیش از حد و عملکرد ضعیف شود. به عنوان مثال، مدلی که بر اساس شرایط نوری روز آموزش داده می شود ممکن است عملکرد خوبی را در تصاویر گرفته شده در روز نشان دهد، اما در شرایط شب با مشکل مواجه خواهد شد. در مثال زیر نشان دادهایم که شرایط مختلف زمان و نور چگونه مجموعه دادههای تصویری متنوعی را به ما میدهد و میتوانیم مدل را برای پیشبینی دقیق در همه شرایط مختلف آموزش دهیم.

همچنین در یک محیط کنترل شده، مانند یک خط تولید، که در آن شما دوربینی دارید که محصولات را از نظر عیوب بررسی می کند، شرایط تا حد زیادی سازگار است. وجود خواهد داشت همان نورپردازی، پس زمینه، و محصولات مشابه یکدیگر. در این سناریو، برای آموزش یک مدل بسیار موثر، به تعداد زیادی مثال نیاز نخواهید داشت.
با این حال، وقتی صحبت از شرایط متغیرتر می شود، مانند یک ماشین خودران که نیاز به کارکرد در کشورهای مختلف و شرایط آب و هوایی دارد، برای آموزش عملکرد قوی به نمونه های زیادی نیاز خواهید داشت.


همچنین اگر یک گروه یا کلاس بیش از حد در مجموعه داده ارائه شود، ممکن است مدلها بایاس شوند. بنابراین هر زمان که مدل با سناریوی متفاوتی مواجه شود که در آن آموزش ندیده باشد، پیشبینی ناموفق است. این امر در مدلهای تشخیص چهره رایج است که در آن اکثر الگوریتمهای تشخیص چهره عملکرد متناقضی را در بین موضوعات نشان میدهند که بر اساس سن، جنسیت و نژاد متفاوت است. داشتن مجموعه داده با تنوع خوب نه تنها منجر به عملکرد خوب میشود، بلکه به رفع مشکلات بالقوه مربوط به عملکرد ثابت در بین طیف کامل موضوعات نیز کمک میکند.

- برچسب گذاری داده ها
بسیاری از برنامه های کاربردی برای یادگیری عمیق در بینایی به برچسب هایی نیاز دارند که اشیا یا کلاس ها را در تصاویر آموزشی شناسایی کنند. برچسب گذاری داده ها بخش مهمی از پیش پردازش داده است که شامل ضمیمه کردن معنی به داده های دیجیتال است. در شکل زیر میتوانید انواع برچسب گذاری را مشاهده کنید.
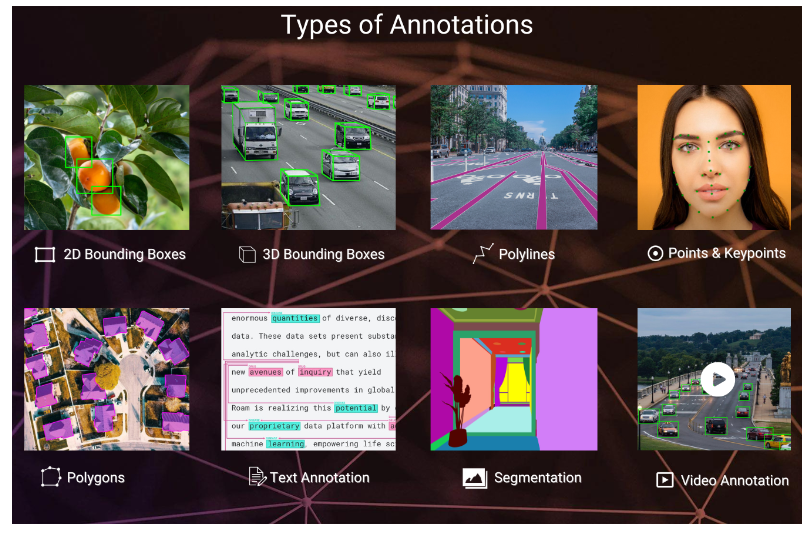
برچسب زدن زمان بر است و مستلزم سازگاری و توجه دقیق به جزئیات است. کیفیت پایین در فرآیند برچسبگذاری میتواند به دلایل مختلفی باشد که همگی میتوانند منجر به عملکرد ضعیف مدل شوند. نمونههای بدون برچسب و برچسبها یا جعبه های مرزبندی ناسازگار دو نمونه از کیفیت پایین برچسبگذاری هستند.
1.4. دقت جعبه مرزبندی
تصور کنید در حال توسعه اپلیکیشنی هستید که در آن عکس می گیرید و به طور دقیق یک شی مانند میز یا وسیله نقلیه را اندازه گیری می کند. برای رسیدن به این هدف، دقت جعبه مرزی باید بسیار بالا باشد. هر گونه عدم دقت در موقعیت یا اندازه منجر به اندازهگیریهای نادرست میشود، بنابراین ضروری است که مدل نمونههای زیادی برای یادگیری برای پیشبینی جعبههای مرزبندی دقیق داشته باشد.


همچنین، شما باید تمام نمونه های اشیا را در تمام تصاویر موجود در مجموعه داده خود برچسب گذاری کنید. اگر به مثال اول نگاه کنید، خواهید دید که فراموش کرده ایم به یک نفر برچسب بزنیم. اگر این کار را انجام دهیم، مدل هوش مصنوعی گیج میشود، زیرا سعی میکند یک جعبه مرزی را در آنجا پیشبینی کند و با عدم برچسب زدن به آن، آن را برای آن پیشبینی مجازات میکنیم، که در واقع درست بود.
2.4. دقت کلاس
فرض کنید در حال توسعه یک سیستم امنیتی هستید که اسلحهها را در دستان افراد تشخیص میدهد، اما بیشتر اوقات آنها چیز دیگری مانند تلفن همراه را در دست دارند. در این سناریو، داشتن دقت کلاس بالا بسیار مهم است. اگر برنامه به اشتباه تلفن همراه را به عنوان یک اسلحه تشخیص دهد، ممکن است به اشتباه واکنش فوری پلیس را آغاز کند. بنابراین، در این مورد، شما میخواهید مطمئن شوید که سیستم بهطور دقیق شی مورد نظر را شناسایی میکند، نه فقط جعبه مرزی اطراف آن. تا زمانی که دقت کلاس بالا است، لازم نیست نگران دقت جعبه محصور باشید، زیرا این مهمترین عامل است.
- تنوع در مجموعه داده
تنوع یک عامل حیاتی برای ایجاد یک مجموعه داده با کیفیت خوب است. مثال یک مدل تشخیص و طبقه بندی تصویر را در نظر بگیرید. اگر این مدل بر روی مجموعه داده ای از تصاویر که نژادهای مختلف سگ را نشان می دهد آموزش داده شود و برای هر نژاد، تصاویری از زوایای مختلف، در شرایط نوری تغییر یافته، از فواصل مختلف، در پس زمینه متضاد و نشان دادن دم، پنجه ها و غیره گرفته شده است. به طور متفاوت، پس این مدل به احتمال زیاد سگ ها را با دقت بیشتری در مقایسه با مدلی که دارای تصاویر مشابه آموزش داده می شود، طبقه بندی می کند. به طور خلاصه، مجموعه دادههای غیرمتنوع بعید است در مقایسه با آنهایی که تمام جنبههای مشکل مورد نظر را پوشش میدهند، بینش مفیدی ارائه دهند.
- افزایش داده ها
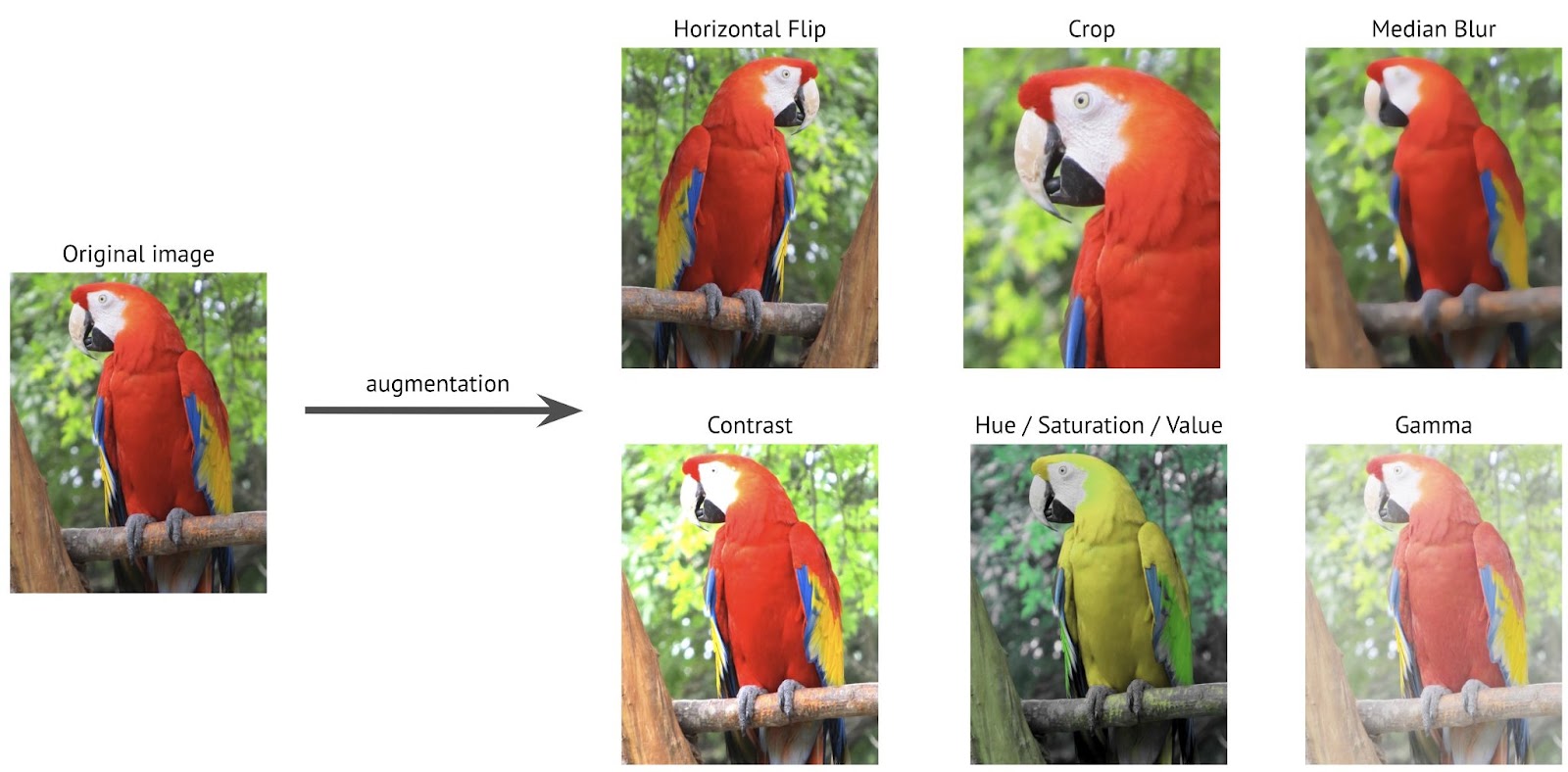
تقویت دادهها یک تکنیک کلیدی برای غنیسازی مجموعه داده است که شامل ایجاد دادههای جدید از دادههای موجود از طریق تبدیلهای مختلف است. به عنوان مثال، در پردازش تصویر، این عمل ممکن است شامل تغییر نور، چرخش یا بزرگنمایی تصویر باشد. این روش تنوع داده ها را افزایش می دهد و یک مدل هوش مصنوعی را قادر می سازد از نمونه های متنوع تری بیاموزد و بنابراین توانایی آن را برای تعمیم به موقعیت های جدید بهبود می بخشد.
افزایش مجموعه داده ها بیش از هر چیز روشی هوشمندانه برای افزایش میزان داده های آموزشی بدون نیاز به جمع آوری داده های واقعی جدید است.
- تعداد کلاس ها
فرض کنید می خواهید مدلی را برای تشخیص طعم های مختلف کپسول قهوه آموزش دهید. این عمل به تعداد زیادی عکس نیاز دارد، به خصوص اگر ۱۰۰ طعم قهوه داشته باشید. شما به بیش از 100 تصویر برای هر طعم نیاز دارید، مانند 800 یا هزار تا، تا اطلاعات کافی برای مدل برای شناسایی الگوها در بین طعمهای مختلف ارائه شود.
از طرف دیگر، اگر می خواهید یک نوع تفنگ مانند یک تپانچه را شناسایی کنید، به تصاویر کمتری نیاز خواهید داشت، زیرا اسلحه ها بسیار شبیه هستند. تعداد تصاویر مورد نیاز نیز به تعداد کلاس هایی که دارید بستگی دارد. بنابراین داشتن تعداد کمتری از دستهها میتواند فرآیند یادگیری را سادهتر و موثرتر کند، زیرا مدل میتواند تمرکز بیشتری بر تفاوتهای ظریف بین دستهها داشته باشد. این رویکرد برای کاربردهایی که نیازمند تشخیص دقیق و سریع هستند، مانند تشخیص فوری اشیا در تصاویر پزشکی یا صنعتی، بسیار مفید است.
- عنوان توصیفی
عنوان final_FINAL_forRealThisTime_v5 را در نظر بگیرید. این عنوان چیزی در مورد مجموعه داده شما نمی گوید جز اینکه برای صدور نسخه مناسب با مشکل مواجه شده اید. عنوان خود را مختصر و آموزنده نگه دارید. به یاد داشته باشید که افرادی که به مجموعه داده شما نگاه می کنند، تمام زمینه هایی که شما درمورد داده های خود دارید را ندارند.
- کلیدهای توصیفی
آیا تا به حال به یک مجموعه داده نگاه کرده اید و نمی توانید بفهمید که چه اتفاقی در حال رخ دادن است؟ بهترین راه برای انجام این کار این است که از کلیدها و برچسب هایی استفاده کنید که برای افراد دیگری غیر از خودتان منطقی باشد. آیا برچسب های استاندارد در دامنه شما وجود دارد؟ از آنها استفاده کنید. باز هم به افرادی فکر کنید که تمام زمینه هایی که شما درمورد داده های خود دارید را ندارند. به آنها کمک کنید تا داده های شما برای همه مفید باشد.
- تعادل کلاس
داشتن یک مجموعه داده متعادل، که در آن تعداد برچسبهای مشابهی برای هر کلاس وجود دارد، مهم است، به طوری که مدل نسبت به اشیا خاص تعصب نداشته باشد. این عمل را می توان با انتخاب دقیق تصاویر و اطمینان از توزیع یکنواخت آنها بین کلاس ها به دست آورد. اطمینان حاصل کنید که همه کلاس ها به خوبی نشان داده شده اند تا از سوگیری جلوگیری شود. مجموعه داده های نامتعادل می تواند منجر به مدل هایی شود که برای کلاس اکثریت بیش از حد برازش شده و در کلاس های اقلیت عملکرد ضعیفی دارند.
- تعدد اشیا در یک تصویر
در یک مجموعه داده بینایی کامپیوتری، وجود چندین شی در هر تصویر میتواند به بهبود دقت و عملکرد مدلها کمک کند. تصاویر با تعداد بیشتری از اشیاء نه تنها مدل را به چالش میکشند بلکه باعث میشوند تا الگوریتمها بتوانند تعاملات و همبستگیهای بین اشیا مختلف را بهتر درک کنند. به عنوان مثال، اگر یک برنامه تلفن همراه ایجاد می کنید که میوه های یک درخت را می شمارد، هر تصویر ممکن است حاوی 500 میوه باشد. در این مورد، ممکن است برای بدست آوردن یک مدل دقیق نیازی به مثال های زیادی نداشته باشید زیرا اطلاعات زیادی در هر تصویر وجود دارد. از طرف دیگر، اگر یک مدل هوش مصنوعی میسازید که توپ را در یک مسابقه فوتبال تشخیص میدهد، ممکن است به نمونههای بیشتری نیاز داشته باشید، زیرا در هر تصویر فقط یک توپ وجود دارد و اطلاعات زیادی برای این مدل وجود ندارد که بتواند با تصاویر کمی به خوبی کار کند. این ویژگی به ویژه در کاربردهای پیچیده مانند تشخیص صحنهها، سیستمهای نظارت و خودروهای خودران بسیار حیاتی است، زیرا در این کاربردها معمولاً تصاویر شامل چندین شی و تعاملات بین آنها هستند.

به طور خلاصه، میزان تنوع در محیط و تعداد اشیا موجود در هر تصویر، فاکتورهای کلیدی هستند که باید هنگام ساخت مجموعه داده در نظر بگیرید.
دادههای واقعی
استفاده از دادههای واقعی و کارآمد برای دنیای واقعی، یکی از اصول اساسی در ایجاد مجموعه دادههای بینایی کامپیوتری با کیفیت است. دادههای واقعی تضمین میکنند که مدلها میتوانند به طور موثری در شرایط واقعی عمل کنند و نتایج قابل اعتمادی ارائه دهند. این نوع دادهها باید نمایانگر تنوع و پیچیدگیهای موجود در دنیای واقعی باشند، از جمله شرایط نوری مختلف، پسزمینههای متنوع و حالتهای گوناگون اشیا. با استفاده از دادههای واقعی، مدلها قادر خواهند بود تا به خوبی در کاربردهای عملی و واقعی، از جمله تشخیص چهره، تحلیل تصاویر پزشکی و سیستمهای نظارتی، عمل کنند.
12. ارتباط
دادههای ویژه مختص به دامنه: مجموعه داده باید دقیقاً با دامنه برنامه مطابقت داشته باشد. به عنوان مثال، یک مجموعه داده برای رانندگی خودران باید شرایط و سناریوهای مختلف رانندگی را شامل شود.
- ملاحظات اخلاقی و قانونی
یکی از مهمترین جوانب کیفیت دادههای بینایی کامپیوتری، ملاحظات اخلاقی و قانونی است که شامل حفظ حریم خصوصی و عدالت در دادهها میشود.
1.13. حریم خصوصی: اطمینان حاصل کنید که مجموعه دادهها حقوق حریم خصوصی را نقض نمیکنند. تصاویر حاوی چهرهها، پلاکهای خودروها و دیگر اطلاعات شخصی باید بر اساس قوانین و دستورالعملهای مربوط به حریم خصوصی پردازش شوند. رعایت این اصول نه تنها به احترام به حقوق افراد کمک میکند بلکه از مشکلات قانونی نیز جلوگیری میکند.
2.13 . تعادل و عدالت: تلاش کنید تا تعصبات موجود در مجموعه دادهها به حداقل برسد و شناسایی شوند. تعصبات در دادهها میتوانند منجر به پیشبینیهای ناعادلانه توسط مدل شوند. به طور مثال، اگر مجموعه دادهها بیشتر شامل تصاویر از یک گروه خاص باشد، مدل ممکن است در تشخیص صحیح افراد از گروههای دیگر ناکام بماند. برای جلوگیری از این مشکلات، لازم است مجموعه دادهها به طور متنوع و متعادل جمعآوری شوند و ارزیابیهای منظم برای شناسایی و رفع تعصبات انجام گیرد.
خلاصه
بنابراین به طور خلاصه، هنگام ایجاد یک مجموعه داده بینایی کامپیوتری برای کار خاص خود، چندین مورد وجود دارد که باید در نظر بگیرید تا اطمینان حاصل شود که مدل قادر به تشخیص موثر و دقیق الگوها خواهد بود. تعداد تصاویر مورد نیاز به تعداد کلاس ها، شباهت بین اشیا داخل همان کلاس و میزان تنوع در تصاویر بستگی دارد. برای تخمین مقدار داده های مورد نیاز برای ساخت یک مدل قوی، درک خوب این عوامل مهم است.
فاکتور مهم دیگری که باید در نظر گرفت کیفیت تصاویر است. بسیار مهم است که اطمینان حاصل شود که تصاویر در مجموعه داده واضح و با وضوح بالا، با اشیا به خوبی تعریف شده و کمترین نویز هستند. این اطمینان حاصل می کند که مدل می تواند نمایش دقیق اشیا را بیاموزد و در سناریوهای دنیای واقعی به خوبی عمل کند.
در نهایت، مهم است که تمام تصاویر موجود در مجموعه داده را با افزودن کادرهای محدود در اطراف اشیا مورد نظر حاشیه نویسی کنید و حتی یک شی را بدون برچسب باقی نگذارید تا مدل بتواند تشخیص صحیح و تمایز بین اشیا را بیاموزد.
در نتیجه، ایجاد یک مجموعه داده بینایی کامپیوتری عالی، گامی حیاتی در ساخت یک مدل هوش مصنوعی موفق و قوی است. تعداد تصاویر مورد نیاز برای ساخت یک مجموعه داده بینایی کامپیوتری عالی به تعداد کلاس ها و شباهت بین مثال ها بستگی دارد. مهم است که این عوامل را قبل از جمع آوری مجموعه داده های خود در نظر بگیرید تا مطمئن شوید که مدل شما در تولید به خوبی کار می کند. با پیروی از این بهترین شیوهها، میتوانید اطمینان حاصل کنید که مدل شما اطلاعات لازم برای تشخیص دقیق الگوها و عملکرد خوب در سناریوهای دنیای واقعی را دارد.
نتیجه گیری
در این مقاله به بررسی عوامل مهم در ارزیابی کیفیت دادههای بینایی کامپیوتری پرداختیم. هر یک از این عوامل نقش مهمی در افزایش دقت و کارایی مدلهای بینایی کامپیوتری ایفا میکنند. آمار بدست آمده از نتیجهی تحقیق و تجربهی تیم متخصص بینا اکسپرتز که شامل چندین متخصص در حوزهی بینایی ماشین است، به هر یک از این عوامل نمرهای از ۱۰ داده است. نتایج این ارزیابیها به شرح زیر است:
- کیفیت داده ها: 8.5
- تعداد نمونه ها: 7
- تغییرپذیری: 8.5
- برچسب گذاری داده ها: 9.25
- تنوع در مجموعه داده: 8
- افزایش داده ها: 6.5
- تعداد کلاس ها: 9.25
- کلیدهای توصیفی/عنوان توصیفی: 8.5
- تعادل کلاس: 5.5
- تعدد اشیا در یک تصویر: 8
- دادههای واقعی: 9.25
- ملاحظات اخلاقی و قانونی: 7.5
پی نوشت:
با توجه به این امتیازات، ما تاکید داریم که رعایت این عوامل میتواند به طور چشمگیری کیفیت مجموعه دادههای بینایی کامپیوتری و در نتیجه دقت و کارایی مدلها را بهبود بخشد. تیم ما همواره تلاش میکند تا با استفاده از این معیارها، بهترین دادهها را برای آموزش و ارزیابی مدلهای بینایی کامپیوتری فراهم کند.